

PDF文件经常用于共享和分发文档,但有时需要将大型PDF文件拆分为较小的部分,以便于管理和分发。本文章将介绍如何使用Python和PyMuPDF库拆分和优化PDF文件,确保拆分后的文件尽可能小且易于处理。
在处理包含数百页的PDF文件时,可能需要将其拆分为多个较小的部分。例如,您可能需要将一个1000页的PDF文件拆分为每个包含200页的5个文件。使用Python和PyMuPDF库,您可以轻松实现这一目标。此外,通过优化拆分后的PDF文件,可以减少文件大小,提高处理效率。
以下是拆分和优化PDF文件的Python脚本的详细说明:
-
导入必要的库: 我们使用
fitz(PyMuPDF)库来处理PDF文件,并使用os库来管理文件路径和目录。import fitz # PyMuPDF
import os
-
定义拆分和优化PDF的函数: 函数
split_and_optimize_pdf接受三个参数:file_path(要拆分的PDF文件路径)、output_dir(拆分后的PDF文件保存目录)和pages_per_split(每个拆分文件的页数)。
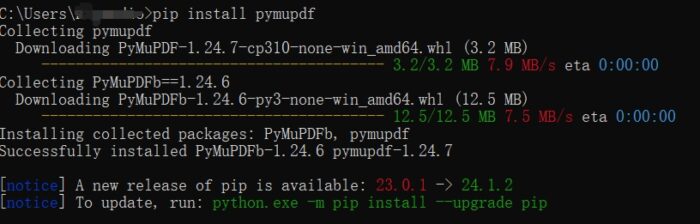
安装PyMuPDF:
代码完整示例-可以直接保存为py格式的文件在python环境下一键运行
import fitz # PyMuPDF
import os
def split_and_optimize_pdf(file_path, output_dir, pages_per_split):
pdf_document = fitz.open(file_path)
total_pages = len(pdf_document)
for start_page in range(0, total_pages, pages_per_split):
split_pdf = fitz.open() # Create a new PDF for each split
for page_num in range(start_page, min(start_page + pages_per_split, total_pages)):
split_pdf.insert_pdf(pdf_document, from_page=page_num, to_page=page_num)
# Optimize and save the split PDF
split_pdf_name = os.path.join(output_dir, f"split_{start_page // pages_per_split + 1}.pdf")
split_pdf.save(split_pdf_name, garbage=4, deflate=True, clean=True) # Optimize the PDF
split_pdf.close()
pdf_document.close()
# Example usage
file_path = r'D:references.pdf'
output_dir = r'D:split_pdfs'
pages_per_split = 200 # Number of pages per split file
# Create output directory if it doesn't exist
os.makedirs(output_dir, exist_ok=True)
# Split and optimize the PDF
split_and_optimize_pdf(file_path, output_dir, pages_per_split)© 版权声明
文章版权归作者所有,转载请注明出处。
THE END